
 MENU
MENU 

Paper award for identifying speaker characteristics in text messages
The goal of the work was to identify seven things about who the subject was talking to just by analyzing text messages.

 Enlarge
EnlargeWhat do your instant messages say about how you communicate – do you text your co-worker very differently than your significant other? Social media and chat services present an abundant source of insight into an individual’s communication patterns and social preferences, and for most people the body of data to draw from is enormous.
By studying a single person’s chat history, researchers can identify characteristics about how he or she communicates and their unique social behaviors. Taken over time, these chats can show how that person develops and changes.
A team in CSE set out to do just that, volunteering their own chat history as data. In a project that earned a Best Student Paper Award at the International Conference on Computational Linguistics and Intelligent Text Processing, PhD student Charlie Welch, Research Scientist Veronica Perez-Rosas, research fellow Jonathan Kummerfeld, and Prof. Rada Mihalcea analyzed a massive collection of one author’s online communications over the course of 5 years to study a number of different speaker attributes and how they are reflected in the language of the messages.
The researchers used a corpus of text messages from one of the author’s personal conversations on Google Hangouts, Facebook Messenger, and SMS text messages. The message set contained nearly half a million messages from conversations held between the author and 104 individuals. The goal of the work was to identify seven things about who the subject was talking to just by analyzing text messages – the recipient’s relative age (was the message going to someone older, younger, or the same age), and whether the recipient is the same gender, a family member, a romantic partner, a classmate, a co-worker, or a native of the same country.
To determine these attributes, the team used a variety of linguistic features, message and time frequency features, stylistic and psycholinguistic features, and graph-based features. In addition, they examined the performance increase gained by using six of the attributes as features to try to classify the seventh.
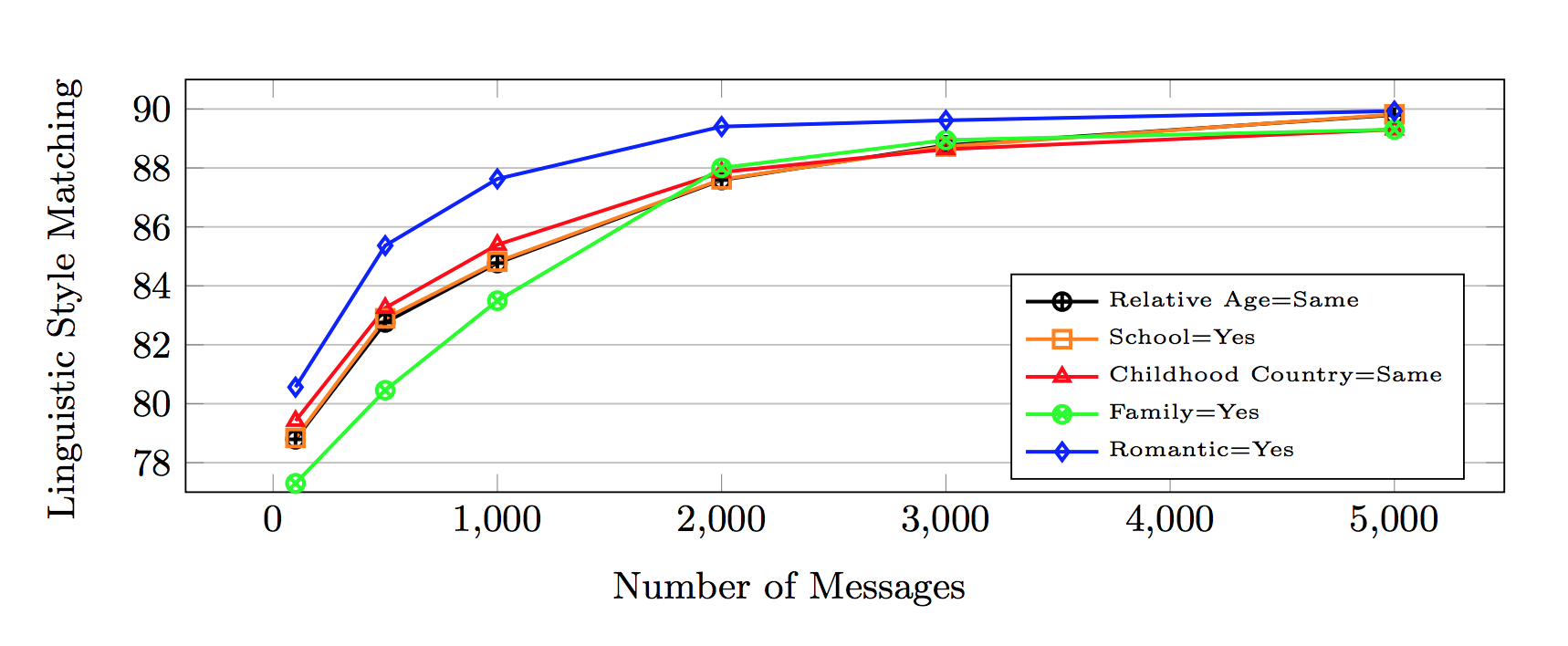 Enlarge
EnlargeThe two main experiments in the paper focused on the usefulness of the features used in the analysis, as well as on and the improvement that can be gained by looking at a larger set of messages as opposed to just a few. They predicted each attribute using first only short context windows of a few messages, and then a larger set of messages over more time.
The evaluations showed an improvement over a system that only uses one of the features at a time, as well as over a baseline system that relies exclusively on message content. Including information such as message timing and frequency led to to gains of 9-14% in accuracy over using only the message text.
According to the authors, this is the first study on speaker attribute prediction using personal longitudinal dialog data that focuses on one person’s dialog interactions with many other speakers.
The paper and the code used to perform the analyses reported in the paper are publicly available from http://lit.eecs.umich.edu.